狠狠射地址 AI大模子泰斗评测:豆包中语对话最强,OpenAI o1推理和数学占优

作家 | 徐豫
裁剪 | 漠影还有不到一周就2025年了,各大外交音娱平台接踵自动掸出“年度答谢”的搜索选项。身处AI元年,AI模子这份年终答卷,当然也少不了。
智东西12月25日报谈,智源磋磨院12月19日发布了FlagEval“百模”评测狂妄,本年国产大模子与外洋大模子战况火暴。
在其闭源大模子评测能力总榜中,字节越过的豆包通用模子pro拿到主不雅评测最高分,OpenAI的o1-mini拿到客不雅评测最高分;多模态模子评测总榜前三名瓜代是OpenAI的GPT-4o、字节越过的豆包视觉清晰模子、Anthropic的Claude 3.5 Sonnet。

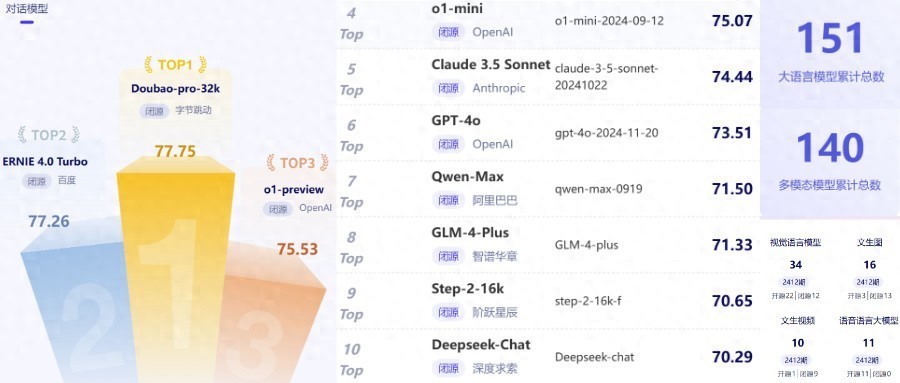
▲谎言语模子评测能力榜单前三名(图片起头:智源磋磨院)
这次评测包含国表里累计100多个开源和营业闭源的话语、视觉话语、文生图、文生视频、语音话语大模子,新增了关于AI模子任务处置能力、果真金融量化交游场景运用能力、辩护能力的考量圭臬。
同期,为了尽可能裁汰数据集败露风险,并减少数据集迷漫度问题,本次评测吸纳了近期发布的数据集、抓续动态更新评测数据、替换了98%的题目以及栽培了题主义难度。
其实前年6月,智源磋磨院就上线了大模子评测平台FlagEval,到目下该平台已有基于AI的缓助评测模子FlagJudge、多模态评测框架FlagEvalMM和针对大模子新能力的评测集。其与北京大学共建的HalluDial是目下大家畛域最大的、对话场景下的幻觉评测集,包含超18000个轮次对话和超14万个回复。
从智源评测最新狂妄不错看出,本年下半年大模子发展更侧重笼统能力栽培与本体运用;多模态模子快速发展,该领域内显现了不少新厂商与新AI模子;话语模子的发展则相对放缓。
获利于多模态能力的栽培,AI模子最新K12学科侦查笼统得分相较于半年前栽培了12.86%,但是仍与北京海淀学生平均水平存在差距。不外,AI模子大批存在“文强理弱”的偏科情况,在英语和历史文科试题的推崇上,已有AI模子超越了东谈主类考生的对等分。
谷歌Gemini 1.5 Pro、阿里巴巴Qwen-VL-Max、Anthropic Claude 3.5 Sonnet、阶跃星辰Step 1V、南洋理工大学LLaVA-Onevision等7家AI模子的英语学科笼统得分高于东谈主类考生;阶跃星辰Step 1V、阿里巴巴Qwen-VL和Qwen-VL-Max、谷歌Gemini 1.5 Pro、南洋理工大学LLaVA-Onevision等12家AI模子的历史学科笼统得分高于东谈主类考生。

▲大模子K12学科侦查历史学科卷面分数榜单前五名(图片起头:智源磋磨院)
日韩成人av电影一、豆包中语对话能力最强,OpenAI o1系列推理水平断层当先基于智源评测狂妄,本年多款国产大模子笼统能力独特外洋知名大模子。
在闭源大模子主不雅评测中,豆包通用模子pro和百度ERNIE 4.0 Turbo的笼统评分均当先于OpenAI的o1-preview、o1-mini、GPT-4o;而在开源大模子主不雅评测中狠狠射地址,阿里巴巴Qwen2.5的笼统评分高于Meta Llama 3.3和Llama 3.1。
主不雅评测更偏重检会大模子中语能力,而国产大模子在中语话语能力上具有大批上风。
因此,从本体笼统评分不错看出,国产大模子占据了闭源大模子主不雅评测榜单的泰半壁山河。其前20名中共有15款国产大模子,占比75%,包括豆包通用模子pro、百度ERNIE 4.0 Turbo、阿里巴巴Qwen-Max、智谱华章GLM-4-Plus、阶跃星辰Step 2等。

▲谎言语模子评测能力榜单主不雅评测前五名(图片起头:智源磋磨院)
不外,要是把大模子放在客不雅评测池子里比较,国产大模子的推崇仍与外洋大模子有着一定差距。
OpenAI的o1-mini得到客不雅评测的最高分64.57,相同属于o1系列的o1-preview,以60.36的笼统评分位列榜单第二。该项评测中阿里巴巴的Qwen-Max和豆包通用模子pro各自的笼统评分为57.60和56.49,与o1-mini之间大致有7分的分差,与o1-preview之间大致有3分的分差。

▲谎言语模子评测能力榜单客不雅评测前五名(图片起头:智源磋磨院)
承接各项细分能力的评分来看,国产大模子更“重文轻理”,主要在推理、数学、代码等方面过期于OpenAI的大模子。举例,即就是侧重中语语境,OpenAI o1-preview仍拿到主不雅评测任务处置板块的最高分85.37,与第二名的79.52分和第三名的77.41分比拟当先上风较为彰着。
二、多模态评测,国产大模子各擅胜场据智源磋磨院调研,本年市面上面部模子的多模态能力得到大幅栽培,上半年参评的模子大批无法生成正确的中语翰墨,但年末参评的头部模子一经具备中语翰墨生成能力。
从这次多模态模子评测数据来看,视觉话语模子平均排名前三离别是OpenAI的GPT-4o、豆包视觉清晰模子和Anthropic的Claude 3.5 Sonnet。这三者中豆包的通用学问、翰墨识别等中语能力与其他两家拉开了较大差距,若单看英文图表清晰推崇则Claude的排名最靠前。

▲视觉话语模子名次榜前三名(图片起头:智源磋磨院)
濒临文本、图片、视频、语音等多模态数据的处理时,豆包文生图模子、豆包视频生成模子“即梦P2.0 pro”离别在相应测试中位列大家第二,腾讯Hunyuan Image文生图水平大家第一,快手可灵1.5(高品性版)文生视频水平大家第一,阿里巴巴Qwen2-Audio语音话语水平大家第一。

▲文生视频模子名次榜前三名(左),文生图模子名次榜前三名(右)(图片起头:智源磋磨院)
目下,AI文生图的本领全体趋于锻真金不怕火,但AI文生视频领域仍有较多挑战。现阶段,热点的AI文生视频模子有可灵1.5(高品性版)、即梦P2.0 pro、爱诗科技PixVerse V3、Minimax海螺AI、Pika同名AI模子Pika 1.5等。
其中,位列榜单第一、二名的可灵和即梦均可生成时长10s的视频,所生成的视频在图文一致性上也打成平手,但前者在AI视频果真性和视频质料后起之秀,后者则在AI视频好意思学质料和分辨率上终了反超。
上述几家多模态模子中,只消阿里巴巴的走开源蹊径。关于多模态开源模子的本体后果,智源磋磨院方面称,诚然开源模子架构趋同,即时常接收话语塔和视觉塔的架构,但具体推崇不一。其中较好的开源模子,在图文理衔命务上正在松开与头部闭源模子的能力差距,而长尾视觉学问与翰墨识别,以及复杂图文数据分析能力仍有栽培空间。
三、AI模子更擅长反驳辩题,还可任职金融行业低级岗亭智源磋磨院在AI模子的年末评测中,新拓荒了对其辩护能力和金融量化交游能力的考核维度。
不到3个月前,智源磋磨院推出了一个名为FlagEval Debate的AI模子辩护平台。该平台主要从逻辑推理、不雅点清晰和话语抒发等中枢能力维度,潜入评估AI话语模子的能力互异。
据最新评测狂妄,一方面AI大模子大批短缺辩护框架意志,不具备围绕辩题、以全体逻辑笼统阐发的能力;另一方面AI大模子在辩护中仍然存在“幻觉”问题,给出的论据时常经不起接洽。
比拟于“正方”,AI大模子似乎更相宜作念辩护赛的“反方”。这次评测狂妄标明AI大模子更擅长反驳,各个模子所隆起的辩护维度趋同。不外,遭遇不同的辩题时AI模子间的推崇差距会较为显贵。
总体来看,在FlagEval Debate评测中,Anthropic Claude 3.5 Sonnet、零一万物Yi-Lighting、OpenAI o1-preview的笼统水平名次前三。
而在金融量化交游领域,这次评测发现大模子已具备生成有回撤收益的政策代码的能力,能开发量化交游典型场景里的代码,头部AI模子能力已接近低级量化交游员的水平。
该榜单前5名瓜代是深度求索的DeepSeek-V2.5、OpenAI的GPT-4o、OpenAI的o1-mini、谷歌的Gemini 1.5 Pro和智谱华章的GLM-4-Plus。此外,百度、腾讯、字节越过、商汤、阿里巴巴、百川智能和零一万物等7家国产大模子开发商均有居品上榜。
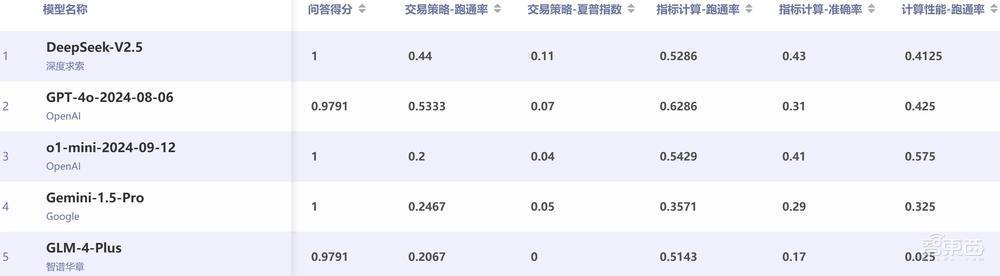
▲金融量化交游评测榜单前五名(图片起头:智源磋磨院)
智源磋磨院主要用学问问答、交游政策的跑通率和夏普指数、瞎想狡计的跑通率和准确率、狡计性能的跑通率这6项瞎想,来比较AI模子的金融量化交游能力。
其中,在学问问答方面,AI模子全体互异较小且全体分数偏高,大部分得分介于0.97到1之间,最低分为Meta Llama 3.1的0.69。但是,濒临本体代码生成任务时,各AI模子互异较大,何况全体能力偏弱。
结语:国产大模子竞争加重,下半场比拼商用质料在这场“各抒已见”中,国产大模子开发商们不仅沉静了其AI模子的中语能力上风,还进一步开发了文生图、文生视频、文生语音等多模态模子后劲。
已往一年,大模子领域也迎来了诸多新拐点,Scaling Law相对放缓、AI模子的数学能力从中学生水平跃升到博士生水平、OpenAI 12月底刚发布的推理模子o3性能接近以致独特了东谈主类水平、背靠AI模子的AI Agent主意和居品热度攀升。
下一步,AI模子将从卷参数目迈向卷运用场景狠狠射地址,催熟营业化落地的服从和效益。